
CDRAG
CDRAG (Clustered Dynamic Retrieval-Augmented Generation): LLM-selected cluster retrieval for RAG — outperforms standard cosine retrieval on legal QA
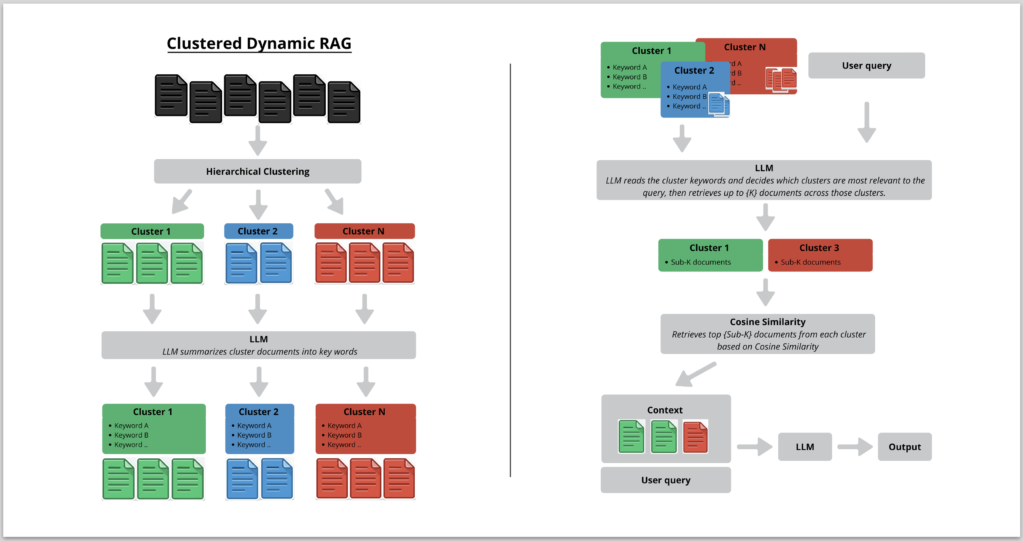
Results
– Faithfulness: +0.51 (12% improvement), the largest gain across all metrics
– Overall quality: +0.34 (8% improvement)
– Conciseness: marginally lower than standard RAG (4.31 vs 4.35)
The gains in faithfulness and overall quality suggest that routing queries to semantically relevant clusters produces more accurate and grounded answers.
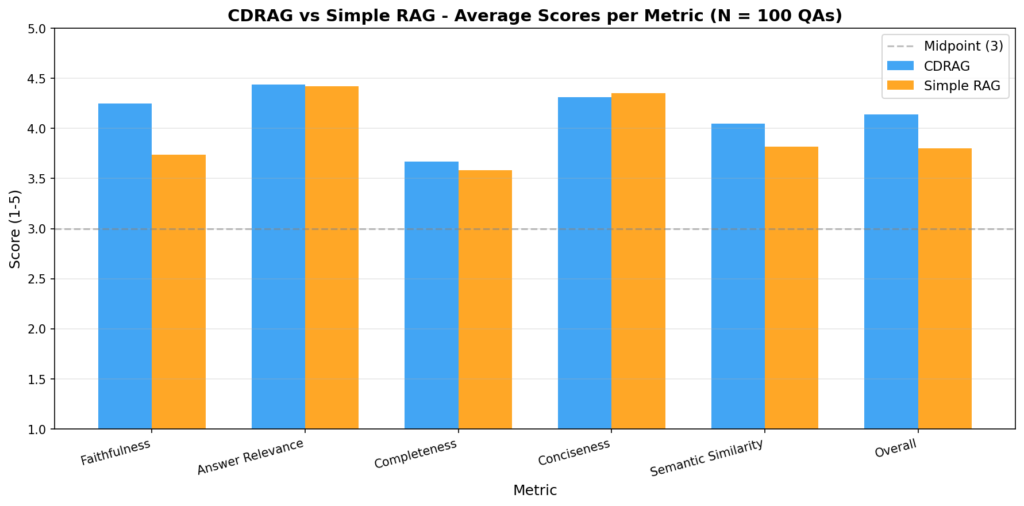
Clustering
In order to create the clusters, I first embedded the documents in the corpus using the sentence-transformers/all-MiniLM-L6-v2 model, which is a lightweight Transformer based on a distilled version of BERT optimized for producing semantically meaningful sentence embeddings. This model maps text into a dense vector space where semantically similar documents are positioned close together, making it well-suited for downstream clustering tasks.
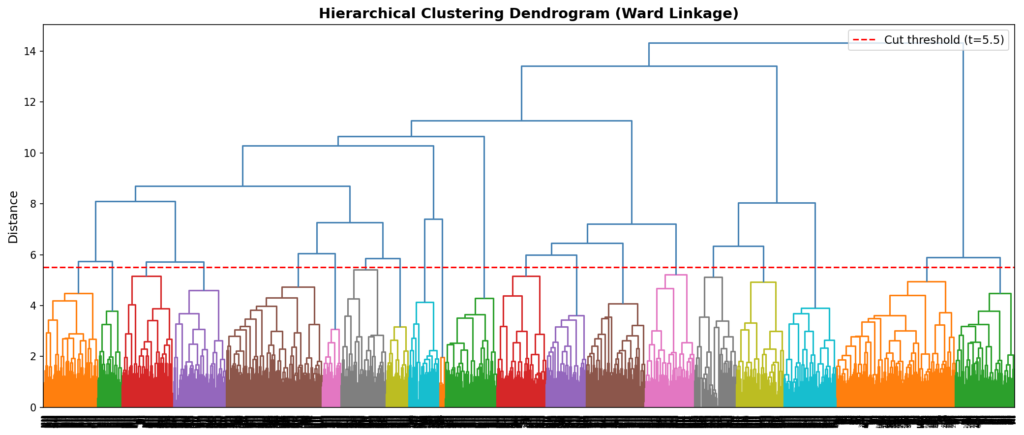
I then applied agglomerative hierarchical clustering (AHC) to these embeddings. During experimentation, I found that using a relatively low distance threshold yielded more coherent groupings. Higher thresholds tended to merge loosely related topics into the same cluster, which in turn reduced the effectiveness of downstream retrieval, as the retrieval budget could not be allocated with sufficient topical precision. The resulting hierarchical structure is visualized in the dendrogram below.
AHC ultimately identified 20 distinct clusters. For each cluster, a language model was used to extract representative keywords that capture the underlying themes. An example cluster is shown below:
Keywords cluster 9:
- beyond reasonable doubt
- onus on the prosecution
- Jury Directions Act 2015
- circumstantial evidence
- reasonable hypothesis consistent with innocence
Leave a Reply